how neural networks think at scale
Marmik Chaudhari, Nishkal Hundia
Introduction
Neural networks like Large Language Models (LLMs) first convert a sequence of input tokens into an dimensional vector by applying a linear transformation. This dimensional vector, called an embedding, then goes through a series of computations or layers like Attention and Multi Layer Perceptrons (MLP) and then is converted back into some output token by applying another linear transformation. These layers perform various linear and sometimes non-linear transformations on the embedding. The intermediate representations formed in the network at the end of each layer are called the hidden/ latent vectors or activations of the network.
The embedding passes through a series of transformations at each layer that extract or encode different kinds of information about the data in the activations. Mechanistic Interpretability (Mech Interp) aims at understanding these activations to reverse engineer how each component of the neural network cause it to produce a specific output. Since activations are high-dimensional vectors, the space of the possible activations is extremely large. This makes it unfeasible to explicitly visualize or analyze (the curse of dimensionality). So how do you understand them? By decomposing activations into independent understandable properties of the data, we can attribute different behaviors of the neural network to specific components. These properties of the data can also be thought of as interpretable “concepts”.
Most real world data has some structure. For instance, the color blue exists in the context of blue things like the sky or water, and words like 'king' and 'queen' share relational properties with 'man' and 'woman.' This occurs because concepts exist in relation to our understanding of other concepts. Language is built from finite vocabulary, has grammar rules, and syntactic structure. Images are composed of visual structures like edges, lines and objects. While low-level visual elements like edges and lines may not seem inherently meaningful on their own, they combine to form recognizable objects, textures, and patterns that do carry semantic meaning. We can think of this structure in terms of the interpretable "concepts"— meaningful ideas that capture important aspects of the data. While one could come up with an infinite number of such concepts, practically, a dataset can be represented by using a finite number of such concepts, say . Furthermore, any reasonable input to the neural network makes use of a very small number of these interpretable concepts compared to the total number of available concepts, which makes the problem of decomposing the activations tractable.
While decomposability is necessary to solve the curse of dimensionality, we also need to be able to access the decomposition somehow. How do we find and extract these concepts from activation vectors? Linear representation of the concepts allows us to do this by determining which directions in the -dimensional space correspond to which independent concepts of the input.
The Geometry of Embeddings
In order to decompose the activations of the neural network, one would want to understand the basis dimensions of its vector space.
The first transformation that an input to a LLM goes through is the word embedding. The vector space of word embeddings is rotational invariant. What does this mean in practical terms?Suppose is the word embedding of a particular word and let be the weight of the embedding matrix such that the . If you apply a linear transformation to the word embedding and apply to the weight matrix, , it will result in an identical model but where the basis dimensions are totally different. So, and .
This demonstrates that the model’s computations are invariant to a change in its basis. In other words, the specific coordinates of the embeddings, or how they are represented in any particular basis, do not matter. What does matter is the relative geometry: how vectors relate to each other through directions, angles, and distances. This leads to a key insight about word embeddings: their space has no privileged basis. There is no “correct” or “canonical” set of axes in which to interpret them. This allows arithmetic like
and to define a “gender” direction by doing
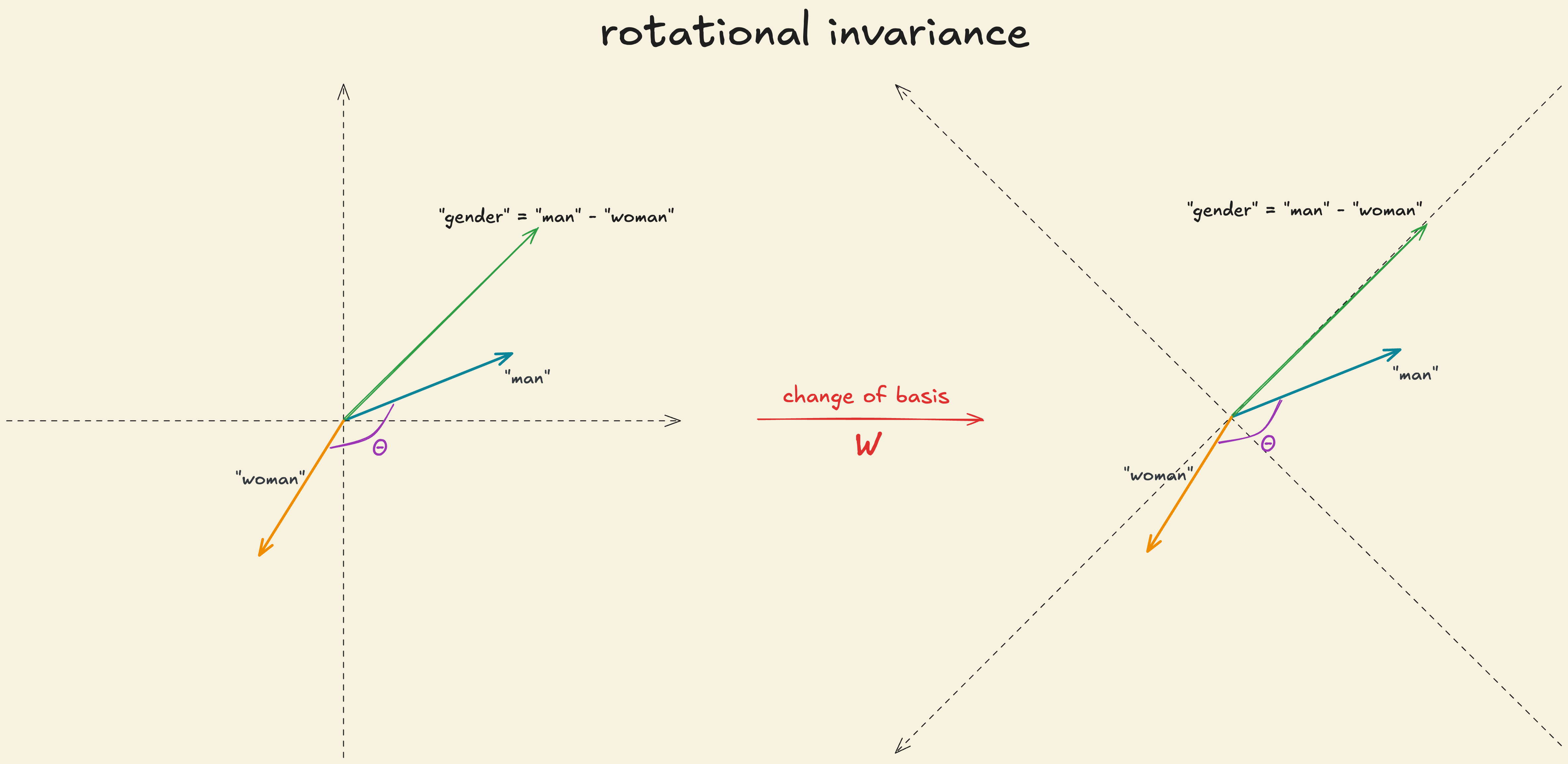
There’s no special relationship between the basis dimension and meaningful concepts. The interpretable concepts are embedded along any arbitrary direction in the vector space, making it non-privileged. In transformers, the residual stream and the attention vectors are non-privileged as well.
Basis of the Activation Space
In contrast, the vector space formed by a network layer’s activations is not like this. It is called the “representation” or activation space.
Consider an MLP that takes a flattened image input vector and produces an output . Then, the activation vector is given by and the output where , and is applied element-wise.
For the sake of simplicity, let’s also assume that the number of independent interpretable concepts, , is equal to the dimensions of the activation space, , meaning each basis dimension or coordinate, , of the activation vector “captures” or detects one of the interpretable concepts. Consider that input vector represents a “yellow car”. The activation vector obtained after applying can be represented as,
after applying element-wise,
The activation functions like essentially “break the symmetry” as observed in word embeddings making certain dimensions more “special”. Since operates independently on each coordinate, it introduces a preference for certain directions by only accepting positive parts of each dimension. Therefore, gives each coordinate a distinct role: whether a neuron activates depends on how much the input projects along that specific axis. This makes the basis privileged: the default coordinate axes matter to the function of the network.
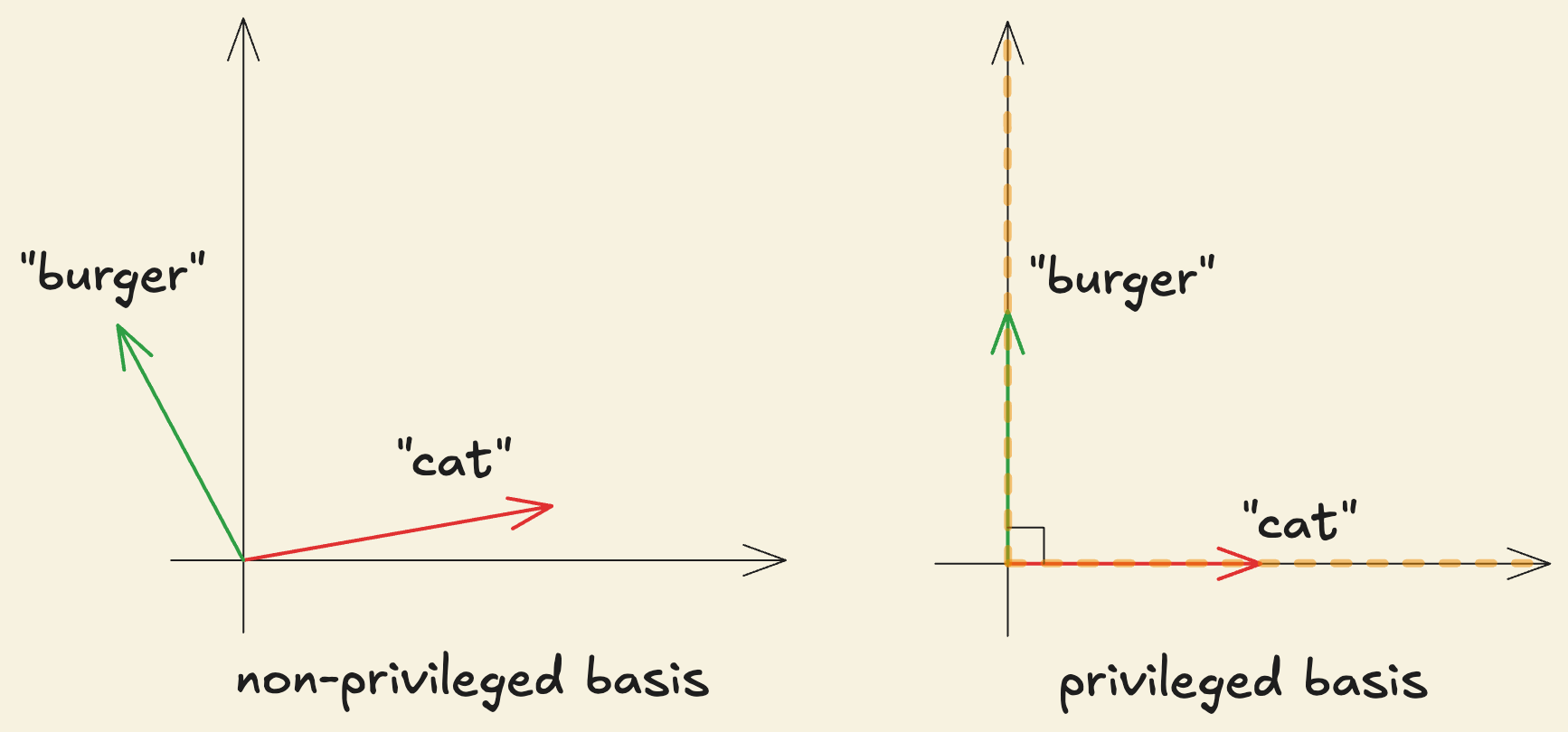
The dimensions of the activation space with privileged basis, i.e. the unique basis directions, are called “neurons”. The term neuron means that each basis dimension behaves like an independent computational unit that can respond to or detect specific interpretable concepts such as the “car shape” or the “yellow color”. From our MLP setup, each row of acts like a template that tries to match a specific interpretable concept. Let’s say is the row vector corresponding to neuron 3 and is a “car shape” detector. The output of the neuron 3, given by , would be non-zero after , indicating strong alignment between and . We call this neuron “active”.
When individual neurons or the basis directions cleanly correspond to a specific interpretable concept, they are called monosemantic. But often, a single neuron is found to be responding to several unrelated but individually interpretable concepts, such as a neuron which responds to cat heads, car shapes, and jesus. Neurons that have grouped several unrelated interpretable concepts together are called polysemantic.

This raises the question of whether neurons — or more generally, the basis directions of the representation space — are the right framework to decompose activations and reason about interpretable concepts, given their polysemantic nature.
The Building Blocks
To address polysemanticity, we need a general abstraction for any interpretable direction in the activation space not necessarily aligned with any single neuron or basis direction. The directions in the activation space that correspond to an interpretable concept or an articulable property of the input such as car shape, dog head, edges are called features. Features can be thought of as being analogous to atoms in molecules. They represent the basic building block from which all neural network representations are constructed. Alternatively, a feature can also be defined as an arbitrary function of the input mapping where is the input (e.g, images, text) and gives the “strength” or “presence” of feature in input . For example, a “car shape” feature would output high values for images with cars and low values otherwise.
But how do these “features” combine to produce the activation vector we observe?
For each of the interpretable concepts or features in the data, denoted by , there exists a corresponding direction in the activation space, represented as . When a neural network processes a specific input, not all features are equally relevant or present. For example, an image might only contain edges and a car shape but no text or a dog head. Each feature has an activation strength associated with it, called “feature activation” , and is denoted by which represents “how much” of a particular concept is expressed in any given input and is a function of the input, . For example, an image with multiple cars would have high activation value for “car shape” features but near-zero activation for “dog-head” features.
Since features are defined as directions in the activation space, decomposing the activations in terms of these features makes the activations themselves linear. Thus, we define a linear representation hypothesis for neural network activations in terms of features: “Any activation vector, for an input containing multiple features, with feature activations, can be expressed as a linear combination of its feature directions, ”. Mathematically,
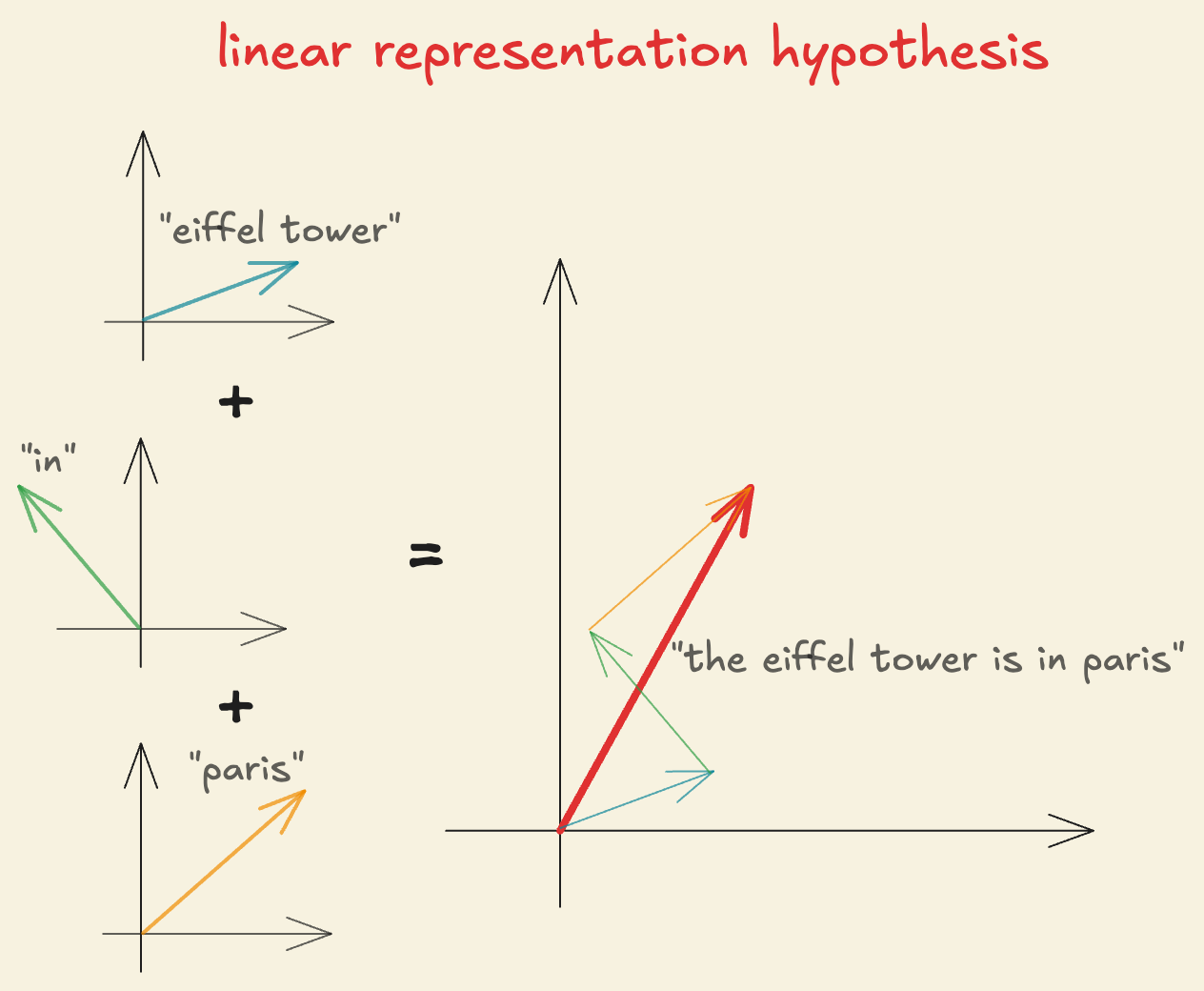
This provides a connection between defining features as both directions in the activation space and as a function of the input. It is also important to note that the process of extracting or representing the presence of features, is non-linear. But once the feature activations are calculated, they are combined linearly to form the activation vector.
A natural question to ask is why should we expect the linear representation hypothesis to be true given that neural networks have non-linear functions like and acting on the activations at various layers.
Neural networks are built with linear functions along with some non-linearities. But the majority of the computations inside a neural network are linear functions (scales due to matrix-matrix multiply) while the non-linearity comprises of a very small part of the entire computation (scales since its element-wise) (in FLOPs).
More importantly for understanding neural networks, linear representations have some key benefits:
- Each neuron can be thought of as detecting a specific pattern by taking the dot product of the input, , with its weight vector, , and gives an activation score. If the neuron is detecting feature then the activation, varies linearly with the strength of the feature . The dot product provides a natural way to do such “pattern” matching.
- If the activation of a previous layer, is represented linearly by and the pre-activation value of a neuron in the next layer, is defined as then substituting in the pre-activation,
where represents the alignment between neuron and feature . This allows the neuron to selectively respond to any individual or combination of features in a single computational step making the features “linearly accessible”. If a feature was represented non-linearly, then the model would not be able to do it in a single step.
- Representing features as directions also allows for non-local generalization, for example, if you learn that features and combine to produce output , you can immediately generalize to any new combination of features and even if you’ve never seen that exact combination before.
Furthermore, monosemantic neurons can be thought of as special cases of features as directions in the representation where it perfectly aligns with a privileged basis direction in the representation, i.e. where is the standard basis vector of feature . The activation vector can be then represented as,
The decomposition of the activation vector in this case is trivial as each coordinate directly tells us the activation strength of feature . For example, the decomposition of an activation vector representing “dog-head” would then look like
A privileged basis is a necessary condition for interpretable neurons. Without it there’s no reason to expect any particular direction to be special. However, it doesn’t guarantee that features will be aligned with a privileged basis direction. In real world data there are far more interpretable concepts than neurons: , so most features cannot be aligned with the privileged basis directions. You can only have at most orthogonal directions in an -dimensional space. The neural network faces an interesting choice during training: either represent the most important features monosemantically (aligning with the privileged basis directions) and ignore the remaining features, or represent more than features by sharing neurons, accepting some noise or interference.
Usually, a network chooses to pack multiple feature directions into a single neuron which results in neurons being polysemantic responding to several unrelated features. A natural follow-up to ask is whether neural networks can noisily represent more features than they have neurons.
The Superposition Hypothesis
Consider any two features and with their directions represented as , respectively. When multiple features are active simultaneously with activations , the activation vector is . The presence or activation of feature in can be calculated as . So, can be rewritten as,
The term measures how aligned feature direction is with . For a neuron to be monosemantic and represent feature , we need (be orthogonal to every other feature direction) and . Since , we cannot make all feature directions and orthogonal, meaning that for certain feature pairs and where , . Now, the activation of feature becomes,
Furthermore, say for a particular input only feature is actually present with and is not present (), then
This creates the interference problem where, when feature activates with , it causes feature to activate even when since and are not orthogonal. When , the term represents interference that feature causes in the direction of feature . The interference problem seems to suggest that representing features in a -dimensional space is sub-optimal due to the unavoidable “false” activation between non-orthogonal directions.
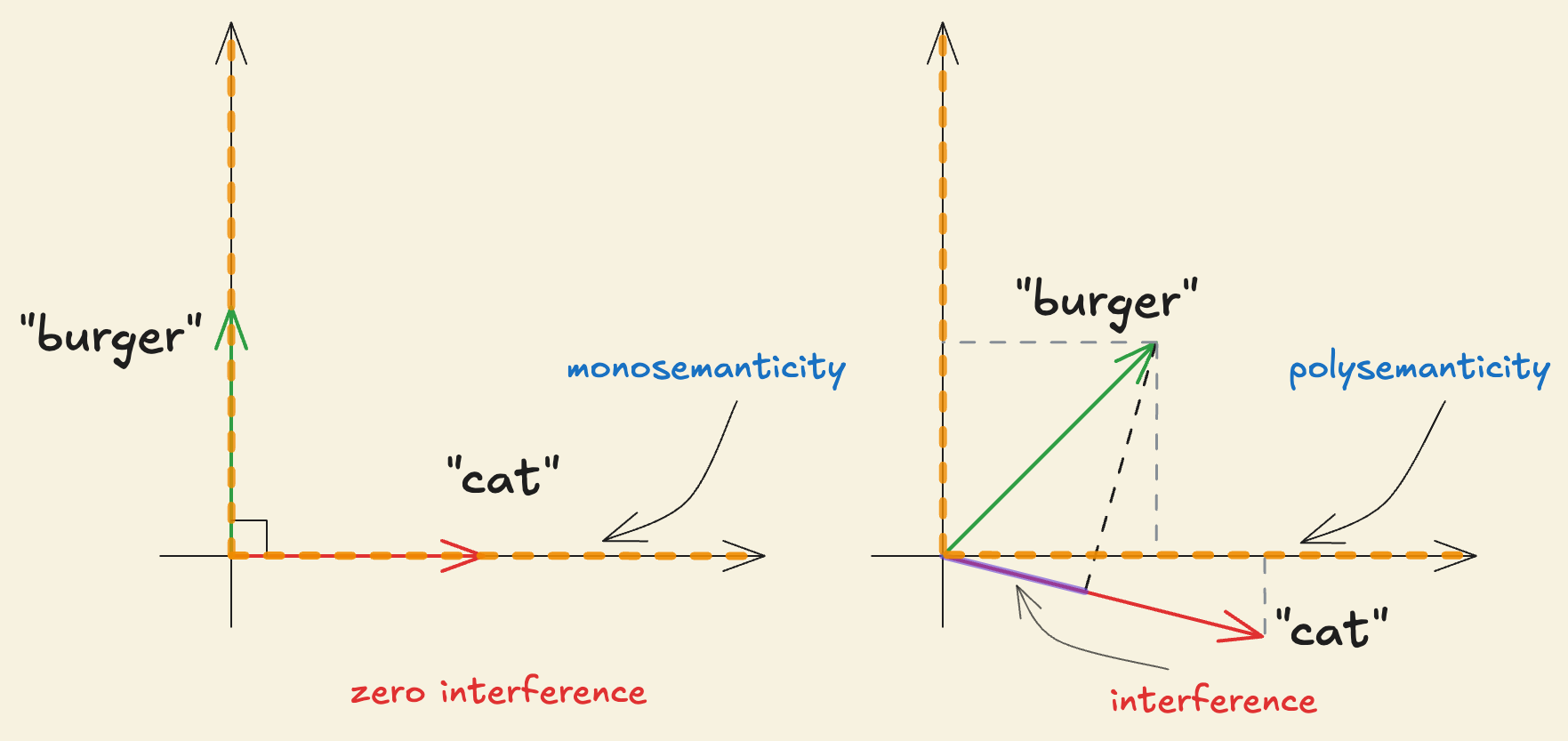
However, neural networks have been found to represent far more features than they have neurons. For example, a vision model with thousands of neurons can effectively represent millions of objects and visual patterns and language models with finite neurons also demonstrate a vast amount of knowledge.
Neural networks exploit a powerful property of high-dimensional spaces to represent far more features than they have neurons. According to the Johnson-Lindenstrauss Lemma, for some small , and any number of features , if is sufficiently large, specifically for some constant , there exists a set of unit vectors in such that for all
Tolerating a small amount of noise or interference allows the network to have many “almost orthogonal” vectors in high-dimensional spaces. Furthermore,
So, the number of features grows exponentially with the number of dimensions. With almost-orthogonal vectors, the interference terms become bounded as
But why do -dimensional spaces have this property?
Let be two random unit vectors in and their dot product is and . This means as increases, each individual component and gets smaller on average by and the product becomes even smaller (by ). Since are sampled randomly, can be positive or negative with roughly equal probability. The sum of over components cancels out roughly with very small remaining terms, , making and almost orthogonal. High-dimensional spaces allow us to extend this phenomena from two nearly orthogonal vectors to exponentially many. When we add more vectors to our space, each new vector eliminates a very small fraction of the space. This allows us to have exponentially many almost-orthogonal vectors.
In language or vision models, the text or image data might contain millions of possible entities like “Martin Luther King”, “Shakespeare”, “Tokyo” or visual properties like “dog head”, “car wheels”, etc., but in any specific text or image input, only a very small fraction of all possible features are actually active. Most types of text or image input don’t talk about “Martin Luther King” or “dog head”. This means that feature are sparse, i.e. rarely active. Most interference terms vanish, as most features have activations and the sum is over a smaller subset of active features given by, . This reduces the interference cost significantly.
Furthermore, different features affect the model’s performance or loss differently. A typical language model’s loss is given as . There are millions of features in data but some of them drive the loss down more than others. For example, when the input text contains Obama, having a “Barack Obama” feature dramatically narrows down the context and makes it easier to predict the next token by constraining the vocabulary and reducing uncertainty rather than, say, having a generic “middle name” feature. The “Barack Obama” feature heavily influences the text around it. Having core linguistic features like “verbs”, “adjectives” and “digits” is also crucial since most of the inputs make use of these concepts and it is important for the network to represent them efficiently to get strong performance (or low loss) and make next token prediction easier. On the other hand, most input text or image is not about “a specific person’s middle name” or “specific breed of dog”. Thus, these features rarely impact the network’s performance and are not as important as the “verbs” or “adjectives” features. This implies that features vary in importance.
Sparsity and feature importance allow neural networks to represent more features than they have neurons by exploiting the property of high-dimensional spaces discussed above. The presence of many sparse features in the underlying data dramatically reduces the interference cost. Feature importance introduces a hierarchy that guides which features of the input to represent and how much interference to tolerate for less important features. This helps the network represent many more important concepts moderately well, achieving lower loss than if it only represented the top features perfectly (orthogonally). Together, it makes superposition, “representing more feature than neurons”, an optimal strategy.
Concretely, the superposition hypothesis details how features are represented as almost orthogonal directions in the activation space. This, in turn, means that one feature activating looks like other features slightly activating (interference). The hypothesis also implies that especially important features might get dedicated neurons or almost orthogonal directions, making them monosemantic. For example, in vision models like Inception V1, critically important features like “curve detectors” or “high-low frequency detectors” have been seen to get dedicated neurons. The rest of the features that have categorically less importance may need to share the activation space and may not align with a specific neuron, making them polysemantic.
One alternate way to think about the superposition hypothesis is that a neural network is effectively a “compressed, noisy” version of a much larger, idealized network. In this hypothetical larger network, each neuron would correspond to exactly one of the infinite interpretable features with zero interference between features, creating a perfectly disentangled representation where every feature has its own dedicated dimension. However, the actual network we observe is a low-dimensional projection of the larger idealized network where the idealized neurons are projected on to the actual network as “almost orthogonal” vectors which, from the perspective of neurons, presents as polysemanticity.
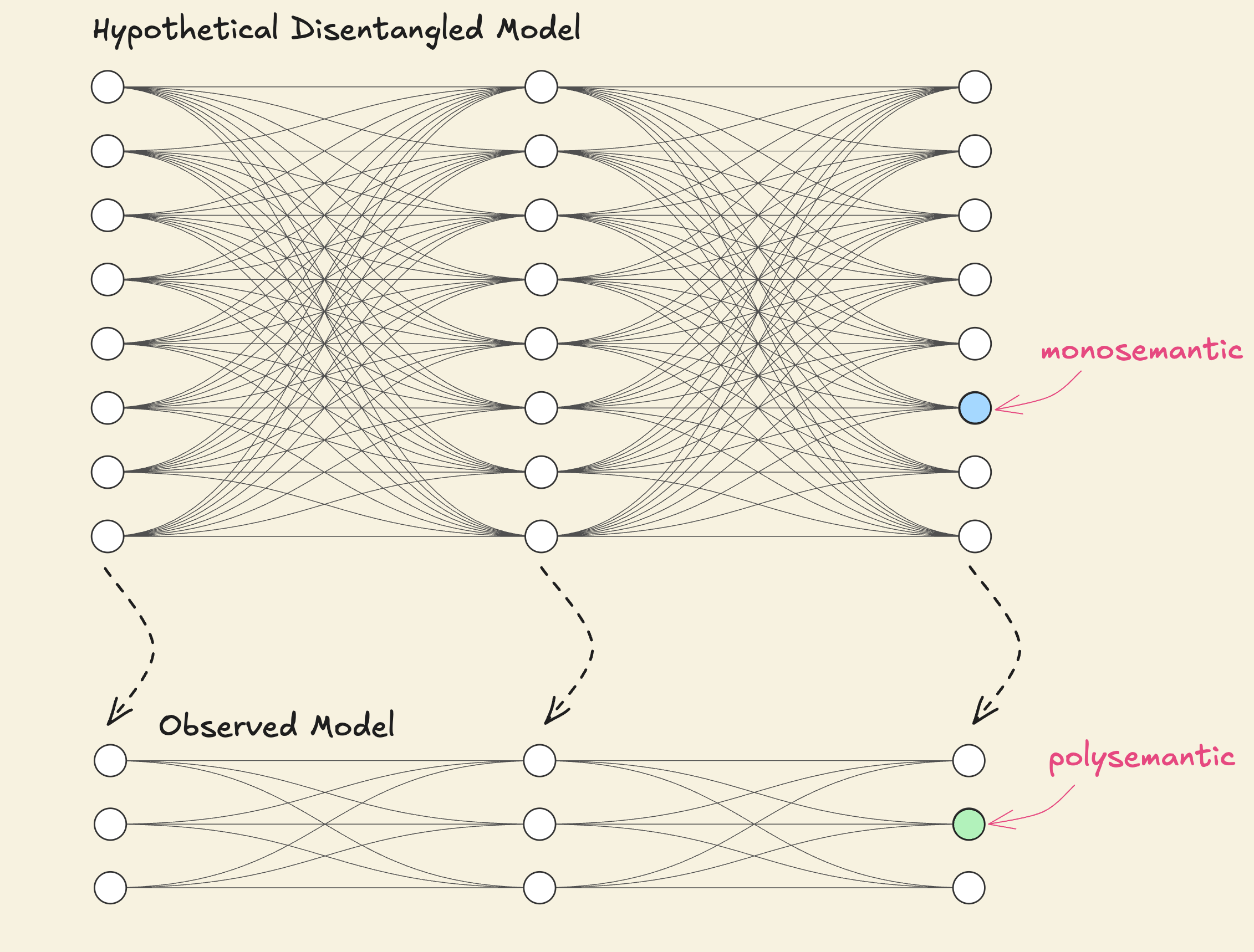
The Challenges of Superposition
In a world with no superposition, we would have one-to-one correspondence between neurons and features and each feature would be represented by an orthogonal direction which perfectly aligns with the basis direction .
With superposition, our activation vector becomes where the feature directions, ’s are not orthogonal or basis aligned. One might try taking the dot product of the activation vector, with feature direction to get the activation strength as
But the activation strength contains other interference terms from all other active features and becomes misleading. We cannot decompose the activations in terms of pure features which obstructs the fundamental goal of mech interp.
Secondly, to confidently attribute certain behaviors, like deception or manipulation, to a model (or confirm their absence), we need the ability to identify and enumerate over all features it represents. This provides us with a universal quantifier over the fundamental units of a neural network. Without superposition in a privileged basis, enumerating over features would be as simple as enumerating over neurons since each neuron would represent a feature. However, with superposition, the number of features that exist in the activation space is unknown due to polysemantic neurons. This obstructs the ability to enumerate over the features.
Solutions
The connection between superposition and enumerating features also goes the other way. If we’re somehow able to enumerate over features, one can “unfold” a superposed model’s activations into those of a larger, non-superposed model.
If we have an activation vector that represents a compressed combination of features, then how can you “un-compress” it back to identify which features are active? There are unknowns but only equations which is an underdetermined system. Such systems have infinitely many equations and the solutions aren’t unique. For example, for the equation , there’s no way for us to recover as can work as well.
But the problem becomes tractable if your features are sparse. In this case, it is possible to recover the original vector or constituents. For features, the map from the feature activation vector, to neurons as in the network given by, can be represented as
where is the feature direction matrix with each column representing the direction of feature .
This is a standard sparse coding or recovery problem. We want to learn an overcomplete set of basis vectors in the activation space, to represent input vectors, to recover the sparse feature activations, . The advantage of having an overcomplete basis is that our basis vectors are better able to capture structure and patterns inherent in the input data. Furthermore, we introduce an additional criterion of sparsity to avoid having an infinite combination of feature activations or coefficients. The sparsity criterion puts the constraint of reconstructing the input vector using the fewest possible basis vectors and makes the solution unique.
Next, we want to minimize the “reconstruction error” which measures how well our decomposition reconstructs the original activation or input vector and is given as
Furthermore, we introduce an L1 sparsity penalty which encourages most of the feature activations, to be zero or close to zero and is written as
where is the regularization parameter and controls the strength of the penalty.
Combining the reconstruction and sparsity error, the complete objective function for the sparse coding problem is
Since we don’t know either or initially, we perform a two step learning process. First involving learning the feature activations or coefficients, for some fixed feature directions, . Then we take the learned feature activations, and use them to optimize our feature directions with the objective function, over training samples subject to to keep the directions normalized.
Another approach to solving superposition involves simply applying a L1 regularization term to the hidden layer activations, i.e. add to the loss. Intuitively, it kills the features that are below a certain importance threshold, especially if they’re not basis aligned. Getting rid of superposition with such penalty may be fairly achievable but comes at a large performance cost. Notably, superposition seems to significantly benefit neural networks, effectively making the networks much bigger.
Looking ahead
Even though past work demonstrating superposition, how it influences learning, and the geometry of the features in superposition exists, there still remain many open questions to answer. For example, should superposition just go away if we scale the network enough or is there a statistical test for catching superposition? Developing a deep understanding of how the models learn certain behaviors and how learning gives rise to its own world of structure and elegant complexity is an avenue worth exploring. It makes interpretability almost equivalent to the biology of artificial neural networks. We hope to have convinced you of the same.
Thanks to Rome Thorstenson, Benjamin Klieger, Jeremi Nuer, Swastik Agarwal, Pranav Karra, Idhant Gulati and Viraj Chhajed for providing valuable feedback on the draft.
References & Further reading
This work has been heavily inspired from the work on Toy Models of Superposition by Elhage et al. Here are some papers for further reading on related topics.
- Olah, et al., "Zoom In: An Introduction to Circuits", Distill, 2020.
- Gabriel Goh, “Decoding Thought Vector”.
- Stanford UFLDL, “Sparse Coding”.
- Cunningham, et al., “Sparse Autoencoders Find Highly Interpretable Features in Language Models”, ICLR, 2024.
- Elhage, et al., "A Mathematical Framework for Transformer Circuits", Transformer Circuits Thread, 2021.
- Lindsey, et al., "On the Biology of a Large Language Model", Transformer Circuits, 2025.
- Bricken, et al., "Towards Monosemanticity: Decomposing Language Models With Dictionary Learning", Transformer Circuits Thread, 2023.